Statistical Parity
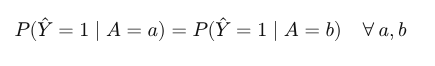
Statistical parity Is a fairness measure to assess how a given predictor behaves when applied in groups having different sensitive attributes. Statistical parity helps answering the question: how many individuals in subpopulation 1 are tagged with prediction 1 in my predictor compared with subpopulation 2 ?. Mathematically is given by the above formula.
Click here to see a video that explains in detail statistical parity.
In Kafkanator, you have an easy method to quickly compute the most common fairness metrics and to display them in a matrix. Download here a notebook to do it.